一種機器學習演算法,由 多棵決策樹(Decision Tree) 組成,也是一種 監督學習(Supervised Learning) 演算法,可以應用 分類(Classification) 和 回歸(Regression) 任務
核心思想是 集成學習(Ensemble Learning),在隨機森林中,每棵決策樹都是一個學習器,最終預測結果是通過對所有決策樹的預測結果進行投票來獲得的
樹的數量:決策樹數量越多,模型準確度通常會越高,但計算成本也會增加每棵樹的最大深度:控制決策樹複雜度,避免過擬合每個節點最少樣本數:控制葉節點純度,避免過擬合特徵隨機選擇的數量:控制每棵決策樹使用特徵數量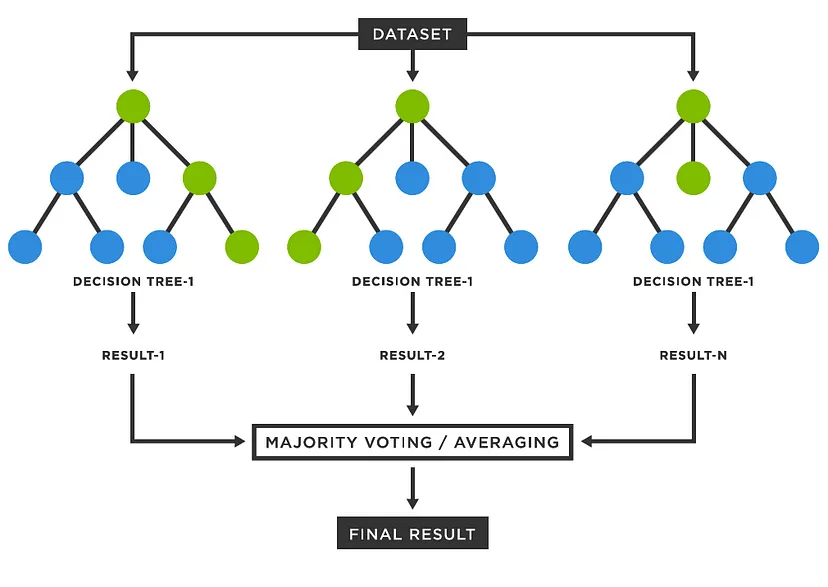
圖片來源:Random Forest
隨機抽樣樣本抽樣:每棵決策樹都從原始訓練數據集中隨機抽取一部分樣本進行訓練,且允許重複抽樣(有放回抽樣)。這使得每棵樹看到的數據略有不同,增加了模型的多樣性特徵抽樣:在構建每棵決策樹時,並不是使用所有的特徵,而是隨機選取一部分特徵進行分裂。這進一步增加了模型的隨機性決策樹生長每棵決策樹都按照傳統決策樹的生長方式進行訓練,直到滿足預定的停止條件(樹的深度、葉節點的樣本數量)
投票預測降低過擬合(Overfitting) 風險:決策樹容易過擬合,而隨機森林通過集成多棵決策樹,可以降低過擬合風險提高準確度:通常可以比單個決策樹獲得更高的準確度能夠處理高維度數據:能夠處理高維度數據,而不會出現 維度災難(Curse of Dimensionality) 問題易於解釋:隨機森林決策過程相對容易解釋,因此是一種可解釋的機器學習模型計算量大:訓練隨機森林模型需要大量的計算資源對異常值敏感:隨機森林對異常值敏感,可能會導致模型性能下降分類問題:信用評級、垃圾郵件分類、疾病診斷迴歸問題:房價預測、股票價格預測異常檢測:網路入侵檢測、欺詐檢測金融風控:預測信用違約、欺詐行為醫學診斷:疾病診斷、預測患者生存期推薦系統:推薦商品、內容圖像識別:物體識別、圖像分類特徵重要性評估:根據每棵決策樹中特徵的重要性,可以評估各個特徵對預測結果的貢獻程度
from sklearn.ensemble import RandomForestClassifier
# 訓練數據
X = [[1, 2], [3, 4], [5, 6]]
y = [0, 1, 2]
# 訓練模型
model = RandomForestClassifier()
model.fit(X, y)
# 預測新數據
new_data = [[7, 8]]
predicted_labels = model.predict(new_data)
print(predicted_labels)
程式碼中,使用 RandomForestClassifier 類別訓練一個隨機森林模型 fit()方法 訓練模型,predict()方法 預測新數據
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 載入鳶尾花資料集
iris = load_iris()
X = iris.data
y = iris.target
# 建立隨機森林分類器
clf = RandomForestClassifier(n_estimators=100)
# 訓練模型
clf.fit(X, y)
# 預測新樣本
new_data = [[5.1, 3.5, 1.4, 0.2]]
predicted = clf.predict(new_data)
print(predicted)
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# 載入鳶尾花數據集
iris = load_iris()
X = iris.data
y = iris.target
# 創建隨機森林分類器
clf = RandomForestClassifier(n_estimators=100)
# 訓練模型
clf.fit(X, y)
# 進行預測
y_pred = clf.predict(X)
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 載入鳶尾花資料集
iris = load_iris()
X = iris.data
y = iris.target
# 分割訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 建立隨機森林分類器
clf = RandomForestClassifier(n_estimators=100, random_state=42)
# 訓練模型
clf.fit(X_train, y_train)
# 進行預測
y_pred = clf.predict(X_test)
# 評估模型性能
from sklearn.metrics import accuracy_score
print("Accuracy:", accuracy_score(y_test, y_pred))
隨機森林是一種強大而靈活的機器學習演算法,在眾多領域都有廣泛的應用。它的優點包括高準確度、能處理高維資料、能評估變數的重要性等,在實際應用中取得了廣泛的成功。然而,隨機森林也有一些缺點,例如:模型較為複雜,調參較為繁瑣


 iThome鐵人賽
iThome鐵人賽